This document provides an overview of the SEM database. It includes:
The information contained in the database includes:
NB while the database consists of a series of conventional data tables, which could each individually be loaded into a spreadsheet or statistical package (e.g. SAS or SPSS), this would be utterly pointless! Almost all questions of any real interest involve relational joins within the database. It is designed so that the appropriate queries will create either a very close approximation to the original reports or life histories for individual members. Appendices A and B illustrate usage.
The database is currently hosted on an Internet-accessible Sun SPARCstation 20 in the Department of Geography ('sun1.geog.qmw.ac.uk'). We are currently using the INGRES relational database package: the data entry system was written using the INGRES 4GL language and is highly specific to the package, so no documentation is provided here; however, the examples of SQL commands and the embedded C program in the appendices are reasonably generic. In the longer term, it is intended to move the database over to Oracle software.
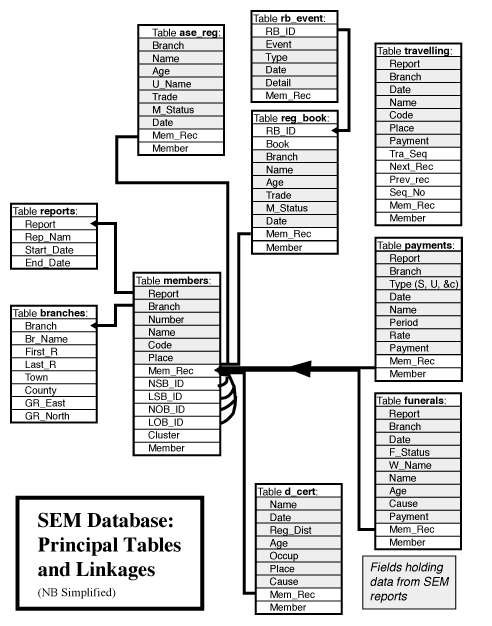
The diagram below shows the structure of the database, arrows indicating how records are linked, and distinguishes fields containing data input from the reports from those holding linkage data. Two points should be obvious: the 'members' table, based on the branch membership lists which appear in every Annual Report is the key to the entire structure; and the database scarcely obeys the relational model despite being implemented using a relational database package. There are various detailed pragmatic reasons for this, but the more general reason is that we have no definitive list of the fundamental entities with which we are concerned: the individual members of the union. There was no master register - the union's Registration Book only covers part of the period and does not appear to list all members joining after it was started - and the union never used a system of membership numbers to identify individuals. We have therefore had to assemble career histories using members' names which were neither unique - there are many a 'Thomas Smith' - nor consistent - the same man might sometimes appear as 'Tom Smyth'.
While the reports provide many clues to help resolve these ambiguities,
each membership history we have constructed must be seen as the result of
a process of inference in which many of the individual decisions can be
contested. The data tables consist partly of raw data which was directly
and unproblematically transcribed from the original sources, and partly
of additional fields we have added which link records together - in particular,
the values of 'member' in the various tables in some senses serve as 'membership
numbers', identifying all records for what we believe to be the same man.
The 'lifeline' program listed in appendix A follows these linkage fields
to assemble 'life histories' for individuals. However, as the next section
explains, the linkage is currently incomplete, while users have the option
of completely discarding our linkage and starting again with the raw data.
Research on the SEM is on-going: we hope to add both more data, extending the system beyond 1876 as well as filling certain gaps, and also further linkage software which will both increase the data available for existing analyses and permit new types of analysis, particularly of mobility. The following limitations should therefore be noted:
The remainder of this document describes each of the individual tables in the database in turn. However, we have tried to standardise the organisation of similar information in different tables, and follow certain other general principles, so please note the following.
Where an entry in the 'contents' column of a table definition appears in bold, it is a Multi-Field Data Structure or Standard Integer Code as defined below.
Certain types of information are naturally organised into multi-field
structures in which the individual fields always have the same names and
types in whatever table the structure appears in. To save space, the table
descriptions that follow refer simply to the structures, indicated by [field
names in brackets], and their internal organisation is explained here:
| Structure | Field | Type | Contents |
| Name | cname | Text (60 chars.) | Forename(s) of member. NB where a name has three elements, such as 'John Jenkin Jones', the division between forename and surname was made by the operator and may be arbitrary. |
| sname | Text (40 chars.) | Surname of member. | |
| suffix | Text (20 chars.) | Suffix to name as given in report, e.g. 'Jun.', 'Sen.', '1st'. These usually only appear where there were two or more men within a branch with identical names, so if a man moved between branches he would not usually retain the suffix. | |
| Date | year | Integer | Year part of date as listed in original report. |
| month | Integer | Month part of date as listed in original report. | |
| day | Integer | Day part of date as listed in original report. | |
| date | Database internal date format | Date value computed from 'year', 'month' and 'day'. NB this will be null if (a) the original report did not give a complete date or (b) the date given was in error - e.g. 30th Feb. | |
| Money | currency | Text (1 char.) |
Currently always null, but handles foreign currencies e.g. US dollars. |
| pounds | Integer | Pound part of the sum of money. | |
| shills | Integer | Shillings part of the sum of money. | |
| pence | Floating point | Pennies and fractions of pennies. | |
| value | Floating point | Computed as ('pounds'*240 + ('shills'*12) + 'pence'. |
To simplify linkage and analysis, certain standard coding systems are used in a number of different tables in the database. These are all stored as integer fields, but in the table definitions are described by the particular type of integer code they contain.
| Report | All records in the tables described in part 2 of the table definitions are drawn from one of the Annual Reports of the SEM, and the value of 'report', included with every record, indicates the volume in question. These values are integers which broadly indicate the year of the report, but the precise period covered by each report varied substantially over the union's history -- only from 1875 onwards do the reports precisely cover calendar years. For earlier periods, the value of 'report' is always the calendar year of the first day covered, but for example the report labeled '1850' covers 5/8/1850 to 25/12/1852, and '1852' covers 25/12/1852 to 25/12/1853. Precise information on the period covered, and a more accurate label for each report, is given in the 'reports' table. | |
| Branch | Similarly, almost every record drawn from the reports also comes from the report of a particular branch of the union, and this is identified by a numerical code. The 'br_names' table is used to supply these codes and contains alternative forms of each branch's name (e.g. 'St Helens', 'St.Helens', etc) while the 'branches' table contains conventional names and other information for each branch code. These codes were in fact allocated in order of each branch's first appearance in the reports; where a branch closed and later re-opened, it is allocated a new code. | |
| Record_ID | Fields whose type is Record_ID play a central role in linking together the database to construct life histories. Each value of this type is a 10-digit numeric code which identifies a particular entry in the 'members' table: | |
| Branch from which record comes | Most significant 3 digits | |
| Report from which record comes | Next 4 digits | |
| Number of the record within branch list | Least significant 3 digits | |
| This system both uniquely identifies each membership record and supplies useful information about it; for example, '21836004' indicates the fourth member listed in the 1836 report of the Bolton branch. Therefore, writing Record_ID values into records of benefit payments links a payment to the relevant membership record. However, these values are also used to link one membership record to another, and in particular the system links each record to the first record for a given man - so these pointers to the first record identify all records for a member, and therefore the relevant Record_ID value identifies not just the one record but the man's history as a whole, and serves as a pseudo-membership number in analytical work. | ||
A few other general points should be noted:
| Codes: | Although various codes are used in the tables to replace text appearing in the Annual Reports, to simplify analysis, the relevant wording in the reports was almost always highly standardised and where there were alternative phrasings we use multiple codes. For example, the 'code' field in the 'members' table summarises the footnotes to the membership lists: if a man was listed as 'Drawn clearance' the code is 'C' while if he 'Joined another branch' it is 'B', even though the two are almost synonymous. Where more specific information was given, we have summarised it as a code but also included it verbatim in the 'comment' field. |
| Comments: | Every data table includes a 'comment' field, which can be used to contain either explanatory information given in the reports or comments by the operator [the latter should always appear in square brackets like this]. Comments in the original sometimes include systematic information which needs to be available for analysis, such as the destination of a migrant or a cause of death, and wherever possible this information is placed in separate fields. |
| Date Values: | Although the tables deposited were created by simply dumping all individual tables from INGRES and removing unnecessary spaces, etc., almost all fields contain either conventional text strings or integer numbers; the few floating point strings were created to hold fractional values such as half pennies or farthings in sums of money or ages expressed in years and months, so there are no problems with truncation. However, the tables do include various dates in a special format used by INGRES but fairly self-explanatory: the day of the month, the month expressed as a three-letter string, and the year, each separated by hyphens - for example, '02-jan-1837'. As the relevant tables always include, in addition, the year, month and day stored as three separate integer fields, dates in other proprietary formats can easily be created. |
| Indexing: | All tables in the RDBMS are indexed by 'member', and many should also be indexed by 'branch' and/or 'report'. |
| Naming: | Given that the SAS statistical analysis software is used for analytical work and directly accesses the data tables via the SAS Access module, we have tried to follow SAS naming conventions for almost all table and field names: maximum 8 characters, beginning with a letter. However, we have broken this rule when necessary to provide more meaningful names. |
(c) Humphrey Southall 1997